- 文章
- 单词
- 今日访问量:5
订单超时怎么处理?我们用这种方案
时间: 2024-01-27 【学无止境】 阅读量:共2379人围观
简介 在企业的商业活动中,订单是指交易双方的产品或服务交易意向。订单超时怎么处理?
1. JDK自带的延时队列
JDK中提供了一种延迟队列数据结构DelayQueue,其本质是封装了PriorityQueue,可以把元素进行排序。
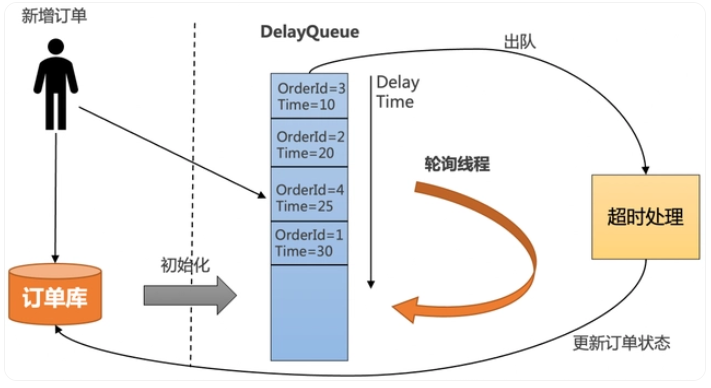
把订单插入DelayQueue中,以超时时间作为排序条件,将订单按照超时时间从小到大排序。
起一个线程不停轮询队列的头部,如果订单的超时时间到了,就出队进行超时处理,并更新订单状态到数据库中。
为了防止机器重启导致内存中的DelayQueue数据丢失,每次机器启动的时候,需要从数据库中初始化未结束的订单,加入到DelayQueue中。
优点:
- 简单,不需要借助其他第三方组件,成本低。
缺点:
所有超时处理订单都要加入到DelayQueue中,占用内存大。
没法做到分布式处理,只能在集群中选一台leader专门处理,效率低。
不适合订单量比较大的场景。
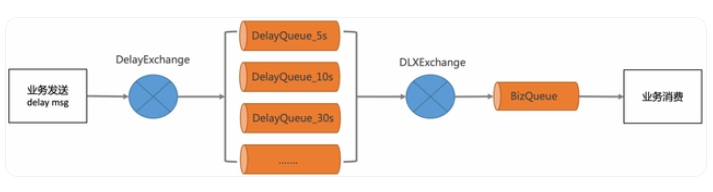
2. RabbitMQ的延时消息
RabbitMQ Delayed Message Plugin是官方提供的延时消息插件,虽然使用起来比较方便,但是不是高可用的,如果节点挂了会导致消息丢失。
优点:
- 可以支持海量延时消息,支持分布式处理。
缺点:
- 不灵活,只能支持固定延时等级。
- 使用复杂,要配置一堆延时队列。
3. RocketMQ的定时消息
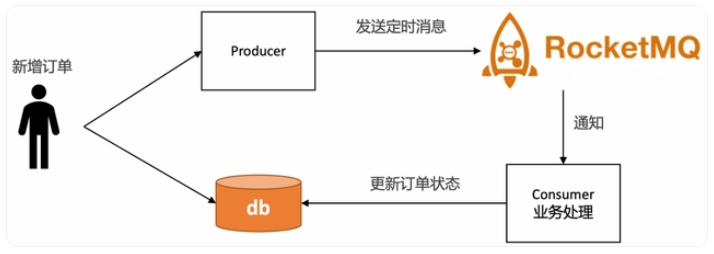
优点
- 精度高,支持任意时刻。
- 使用门槛低,和使用普通消息一样。
缺点
使用限制:定时时长最大值24小时。
成本高:每个订单需要新增一个定时消息,且不会马上消费,给MQ带来很大的存储成本。
同一个时刻大量消息会导致消息延迟:定时消息的实现逻辑需要先经过定时存储等待触发,定时时间到达后才会被投递给消费者。因此,如果将大量定时消息的定时时间设置为同一时刻,则到达该时刻后会有大量消息同时需要被处理,会造成系统压力过大,导致消息分发延迟,影响定时精度。
4. Redis的过期监听
Redis支持过期监听,也能达到和RocketMQ定时消息一样的能力。
Redis主要使用了定期删除和惰性删除策略来进行过期key的删除
定期删除:每隔一段时间(默认100ms)就随机抽取一些设置了过期时间的key,检查其是否过期,如果有过期就删除。之所以这么做,是为了通过限制删除操作的执行时长和频率来减少对cpu的影响。不然每隔100ms就要遍历所有设置过期时间的key,会导致cpu负载太大。
惰性删除:不主动删除过期的key,每次从数据库访问key时,都检测key是否过期,如果过期则删除该key。惰性删除有一个问题,如果这个key已经过期了,但是一直没有被访问,就会一直保存在数据库中。
从以上的原理可以得知[2],Redis过期删除是不精准的,在订单超时处理的场景下,惰性删除基本上也用不到,无法保证key在过期的时候可以立即删除,更不能保证能立即通知。如果订单量比较大,那么延迟几分钟也是有可能的。
Redis过期通知也是不可靠的,Redis在过期通知的时候,如果应用正好重启了,那么就有可能通知事件就丢了,会导致订单一直无法关闭,有稳定性问题。如果一定要使用Redis过期监听方案,建议再通过定时任务做补偿机制。
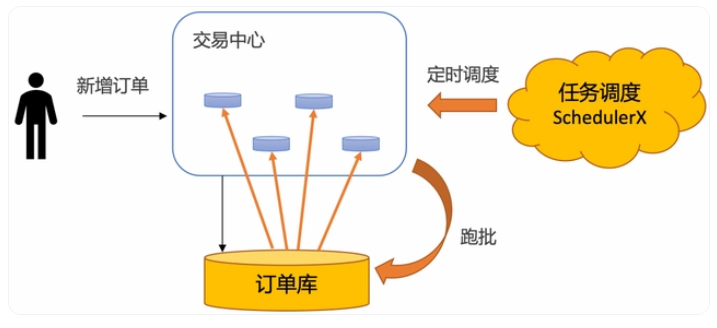
5. 定时任务分布式批处理
定时任务分布式批处理解决方案,即通过定时任务不停轮询数据库的订单,将已经超时的订单捞出来,分发给不同的机器分布式处理。
使用定时任务分布式批处理的方案具有如下优势:
稳定性强:基于通知的方案(比如MQ和Redis),比较担心在各种极端情况下导致通知的事件丢了。使用定时任务跑批,只需要保证业务幂等即可,如果这个批次有些订单没有捞出来,或者处理订单的时候应用重启了,下一个批次还是可以捞出来处理,稳定性非常高。
效率高:基于MQ的方案,需要一个订单一个定时消息,consumer处理定时消息的时候也需要一个订单一个订单更新,对数据库tps很高。使用定时任务跑批方案,一次捞出一批订单,处理完了,可以批量更新订单状态,减少数据库的tps。在海量订单处理场景下,批量处理效率最高。
可运维:基于数据库存储,可以很方便的对订单进行修改、暂停、取消等操作,所见即所得。如果业务跑失败了,还可以直接通过sql修改数据库来进行批量运维。
成本低:相对于其他解决方案要借助第三方存储组件,复用数据库的成本大大降低。
但是使用定时任务有个天然的缺点:没法做到精度很高。定时任务的延迟时间,由定时任务的调度周期决定。如果把频率设置很小,就会导致数据库的qps比较高,容易造成数据库压力过大,从而影响线上的正常业务。
所以一般需要抽离出超时中心和超时库来单独做订单的超时调度,在阿里内部,几乎所有的业务都使用基于定时任务分布式批处理的超时中心来做订单超时处理,SLA可以做到30秒以内。

如何让超时中心不同的节点协同工作,拉取不同的数据?
通常的解决方案是借助任务调度系统,开源任务调度系统大多支持分片模型,比较适合做分库分表的轮询,比如一个分片代表一张分表。但是如果分表特别多,分片模型配置起来还是比较麻烦的。另外如果只有一张大表,或者超时中心使用其他的存储,这两个模型就不太适合。
阿里巴巴分布式任务调度系统SchedulerX[3],不但兼容主流开源任务调度系统和Spring @Scheduled注解,还自研了轻量级MapReduce模型[4],针对任意异构数据源,简单几行代码就可以实现海量数据秒级别跑批。
通过实现map函数,通过代码自行构造分片,SchedulerX会将分片平均分给超时中心的不同节点分布式执行。
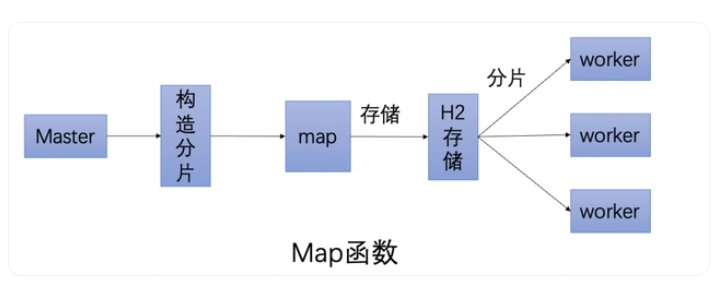
通过实现reduce函数,可以做聚合,可以判断这次跑批有哪些分片跑失败了,从而通知下游处理。
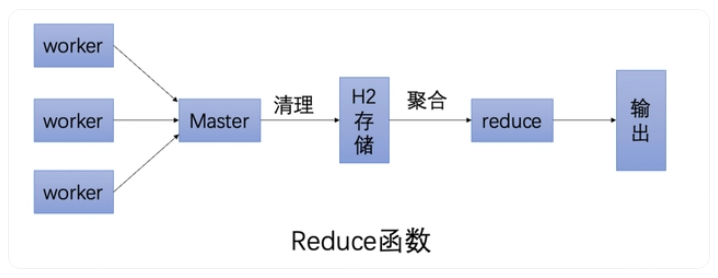
使用SchedulerX定时跑批解决方案,还具有如下优势:
免运维、成本低:不需要自建任务调度系统,由云上托管。
可观测:提供任务执行的历史记录、查看堆栈、日志服务、链路追踪等能力。
高可用:支持同城双活容灾,支持多种渠道的监控报警。
混部:可以托管阿里云的机器,也可以托管非阿里云的机器。
总结
如果对于超时精度比较高,超时时间在24小时内,且不会有峰值压力的场景,推荐使用RocketMQ的定时消息解决方案。
在电商业务下,许多订单超时场景都在24小时以上,对于超时精度没有那么敏感,并且有海量订单需要批处理,推荐使用基于定时任务的跑批解决方案。
 公安备案号 50010302004554
公安备案号 50010302004554